Key-Value caching
Long story short, Key value caching is used to reduce the inference speed of AR models (autoregressive / decoder-only). It does so by caching the already computed attention scores (K and V) of previous 1– t-1 tokens. While the generated token is t.
Inference refers to the process of using a trained model to make predictions or generate output for new, unseen input data. In other words, it’s the process of applying the model to real-world data to get a result or prediction.
Starting from single token
let’s say, we start with single token. During inference, when generating output sequences token-by-token, the sequence length increases by 1 at each step. Here’s how it works:
- Initial input: A single token (sequence length 1)
- Generate output token 1: SL becomes 2 (input token + generated token)
- Generate output token 2: SL becomes 3 (input token + 2 generated tokens)
- Generate output token 3: SL becomes 4 (input token + 3 generated tokens)
… (continues)
If you see, we are again and again calculating the Key and Values for last t-1 tokens. Because attention mechanism needs to consider K, Q, V for all previous tokens (equals to context length) when generating each new token, resulting in a quadratic increase in computation with respect to sequence length.
KV caching addresses this issue by storing the computed Key (K) and Value (V) matrices for each token generation step. This allows the model to reuse these cached matrices instead of recomputing them from scratch at each step, reducing the computational cost.
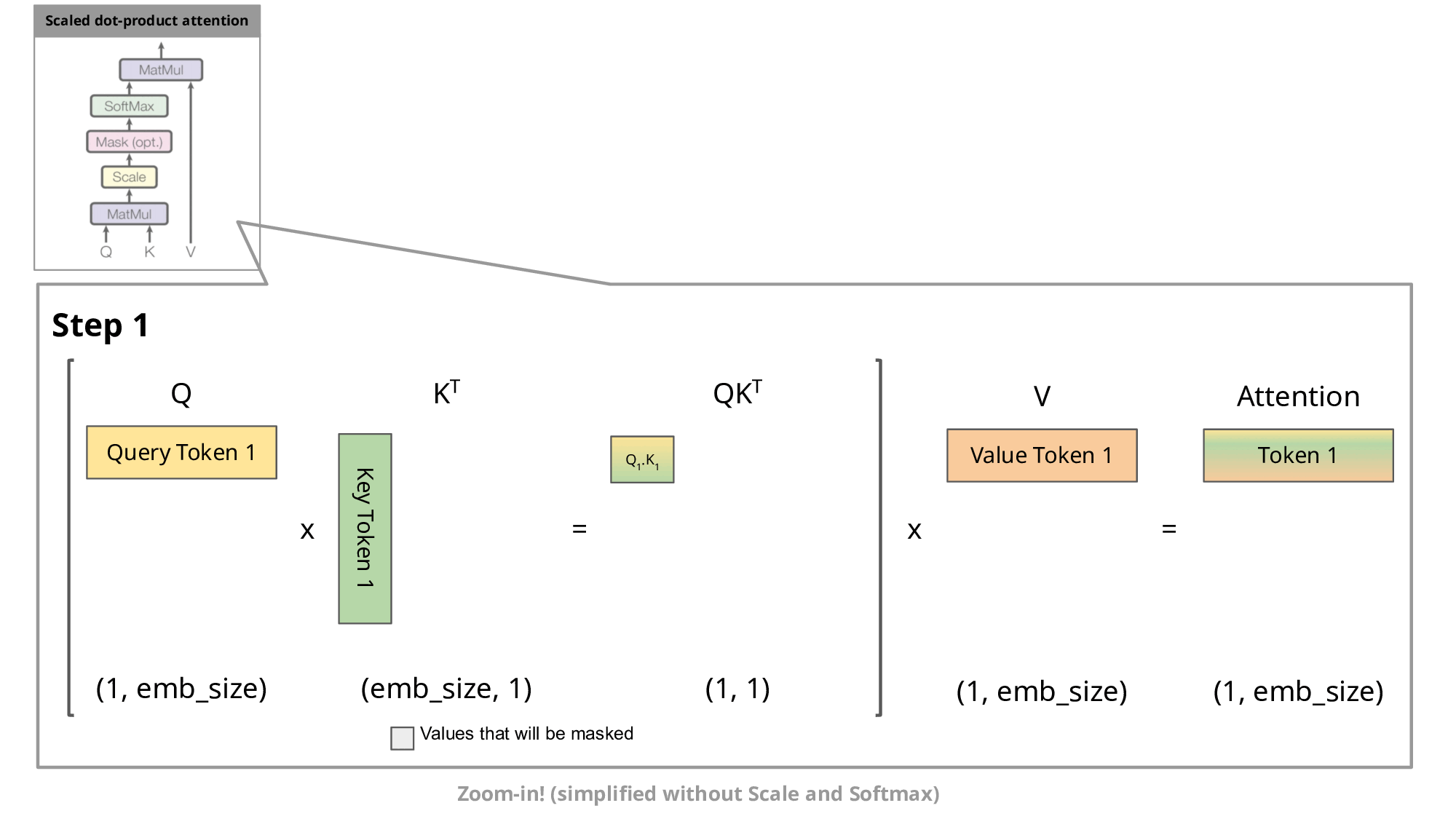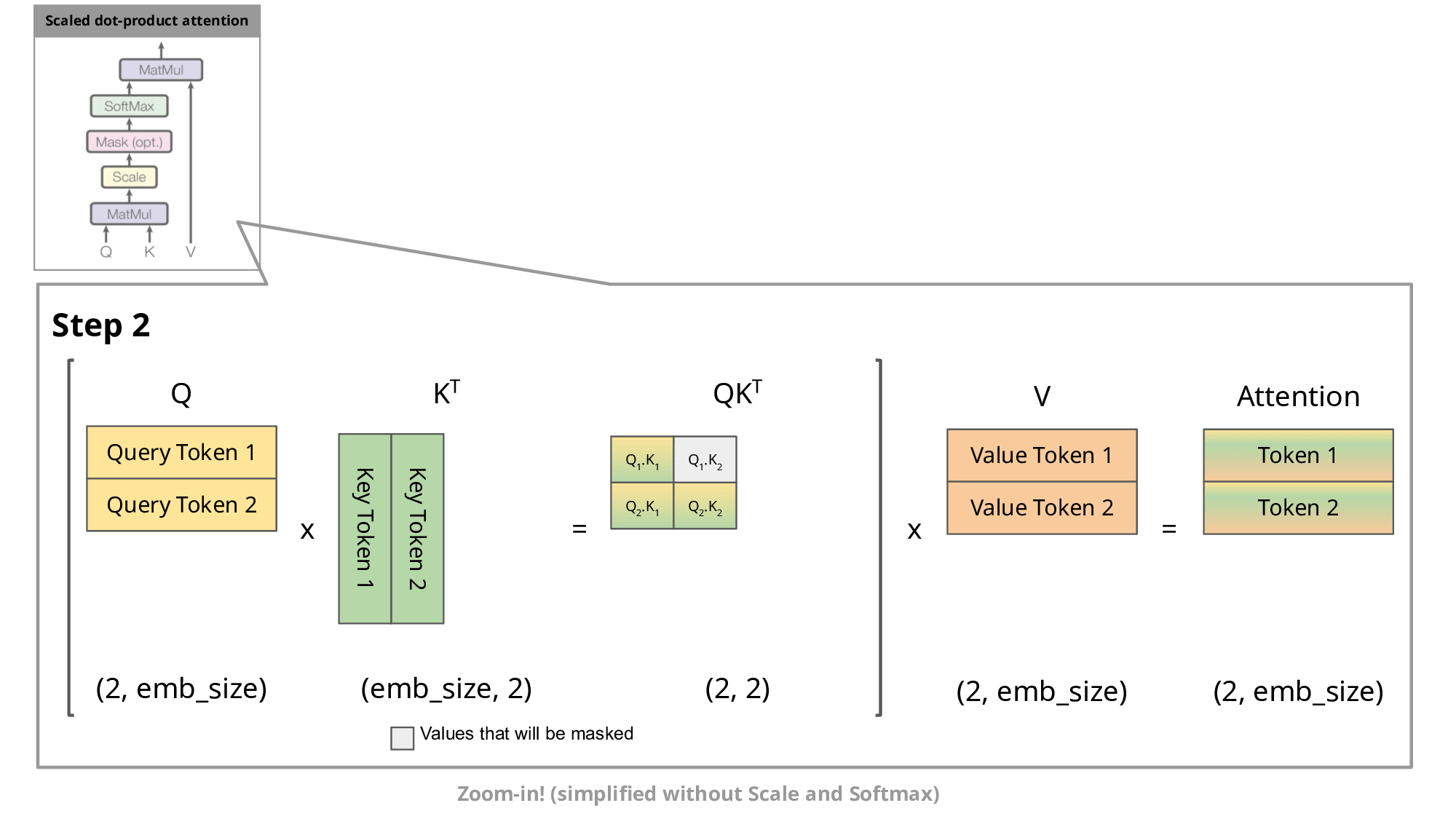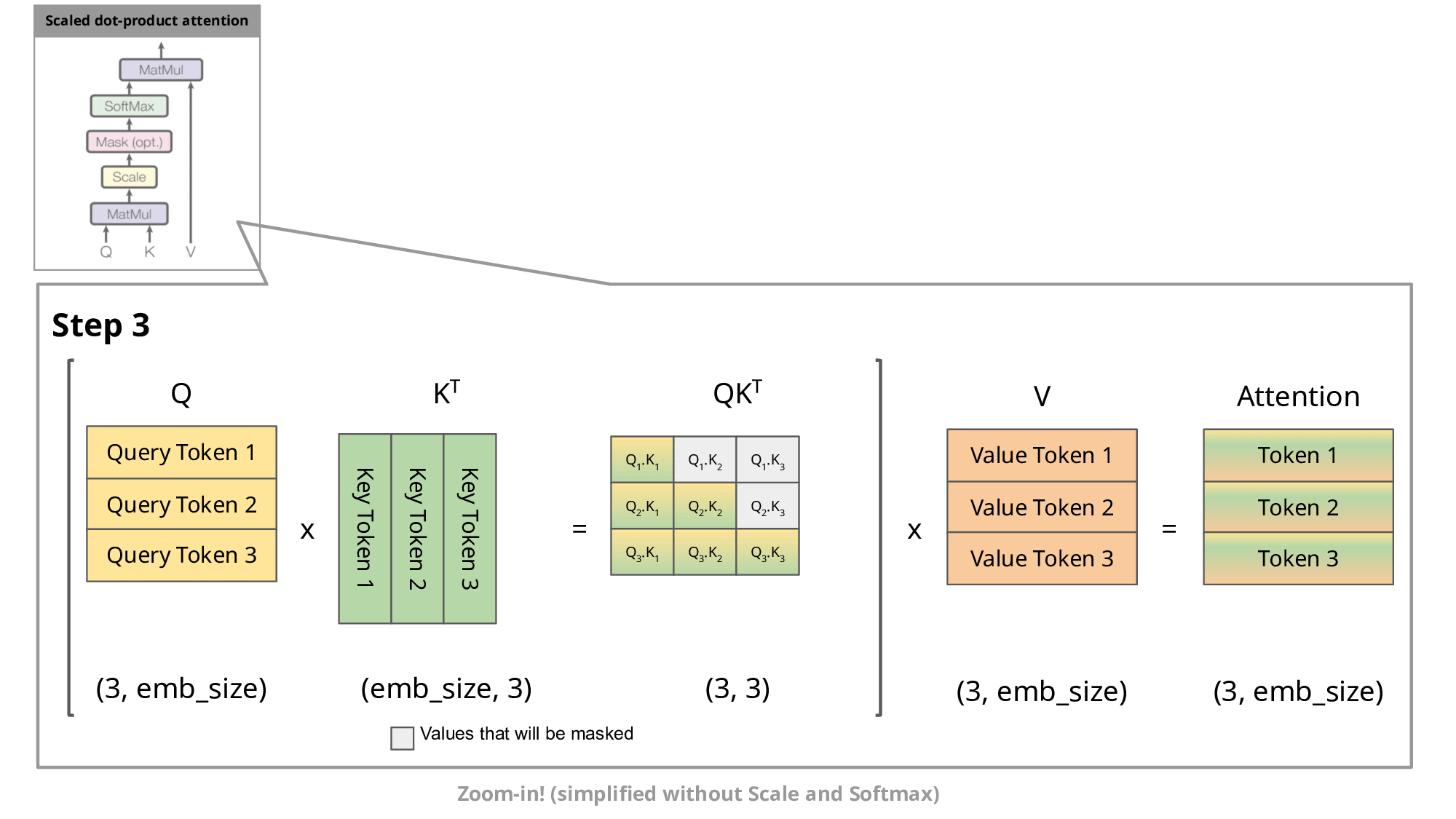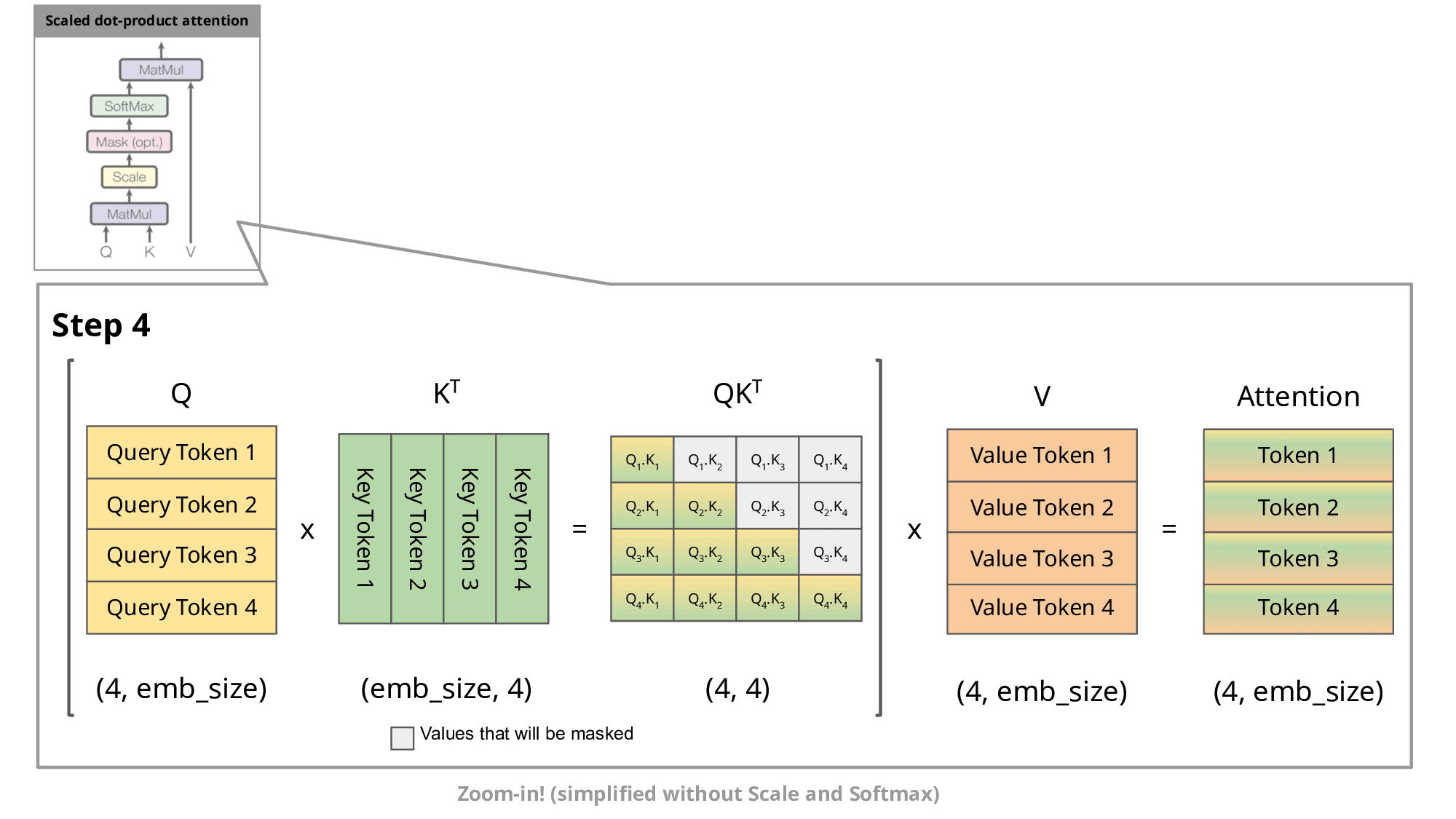
With KV caching, the sequence length still increases by 1 at each step, but the model can efficiently reuse previously computed K and V matrices, mitigating the quadratic increase in computation. This makes long-range generation more efficient and scalable.
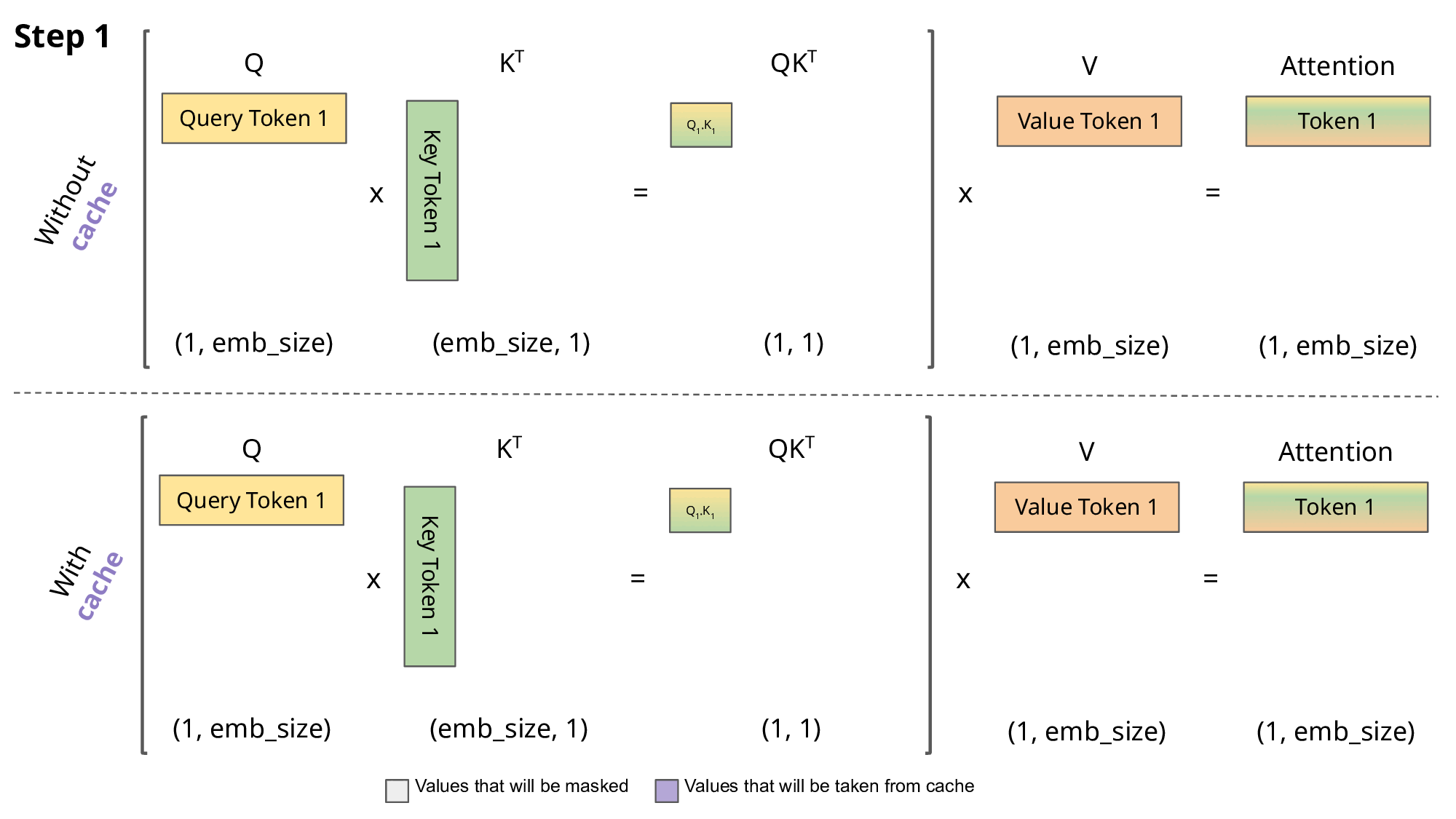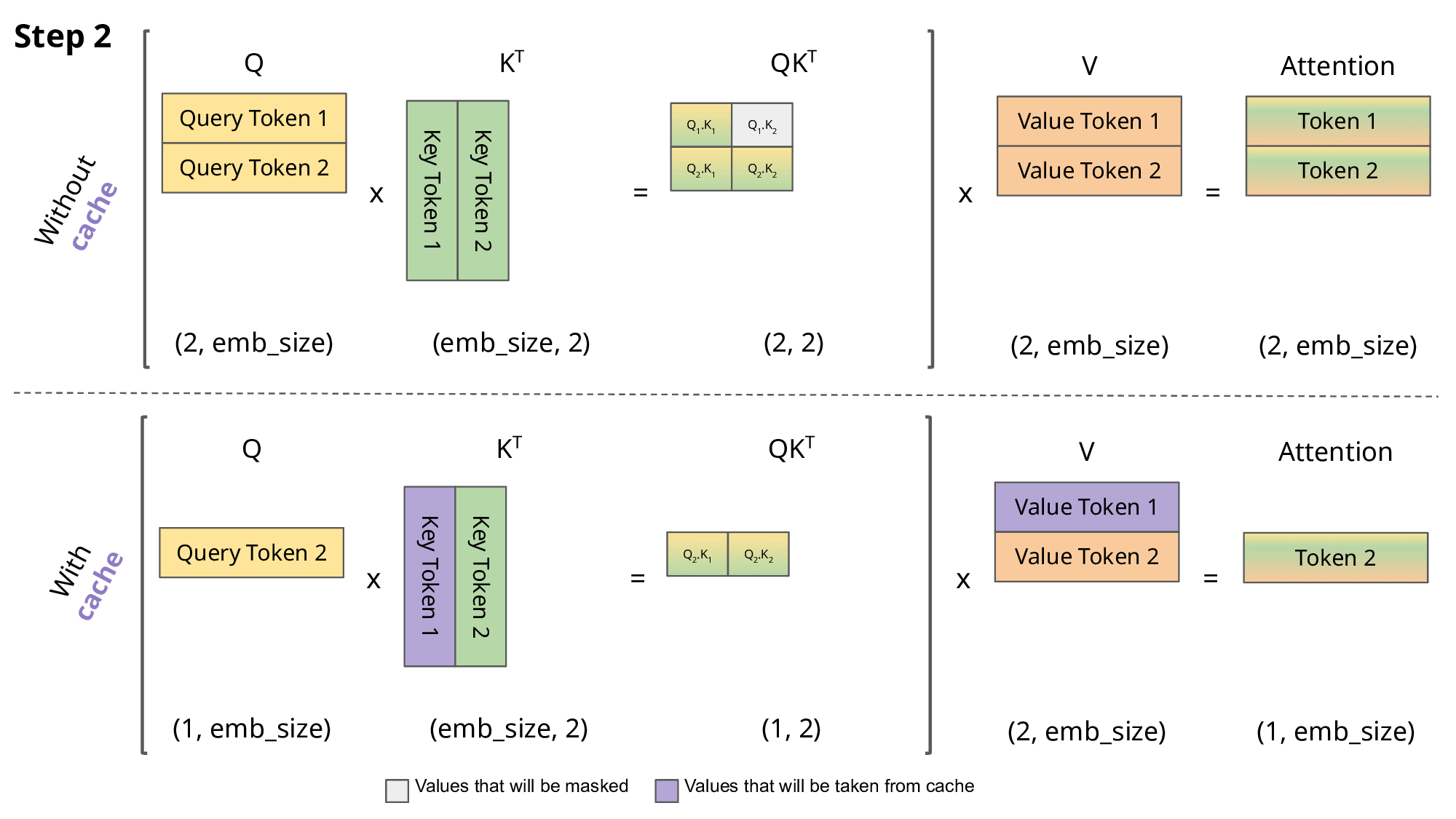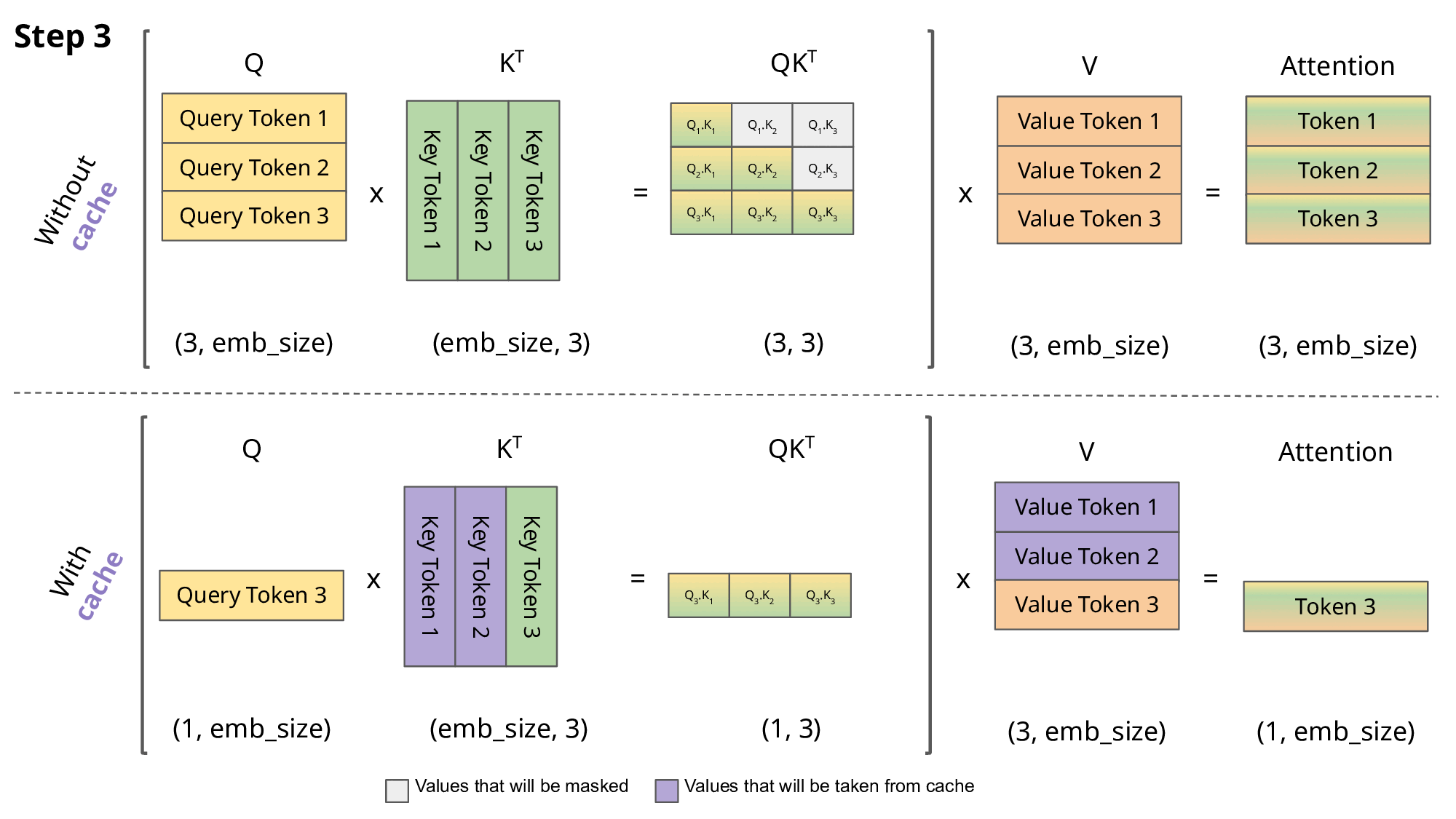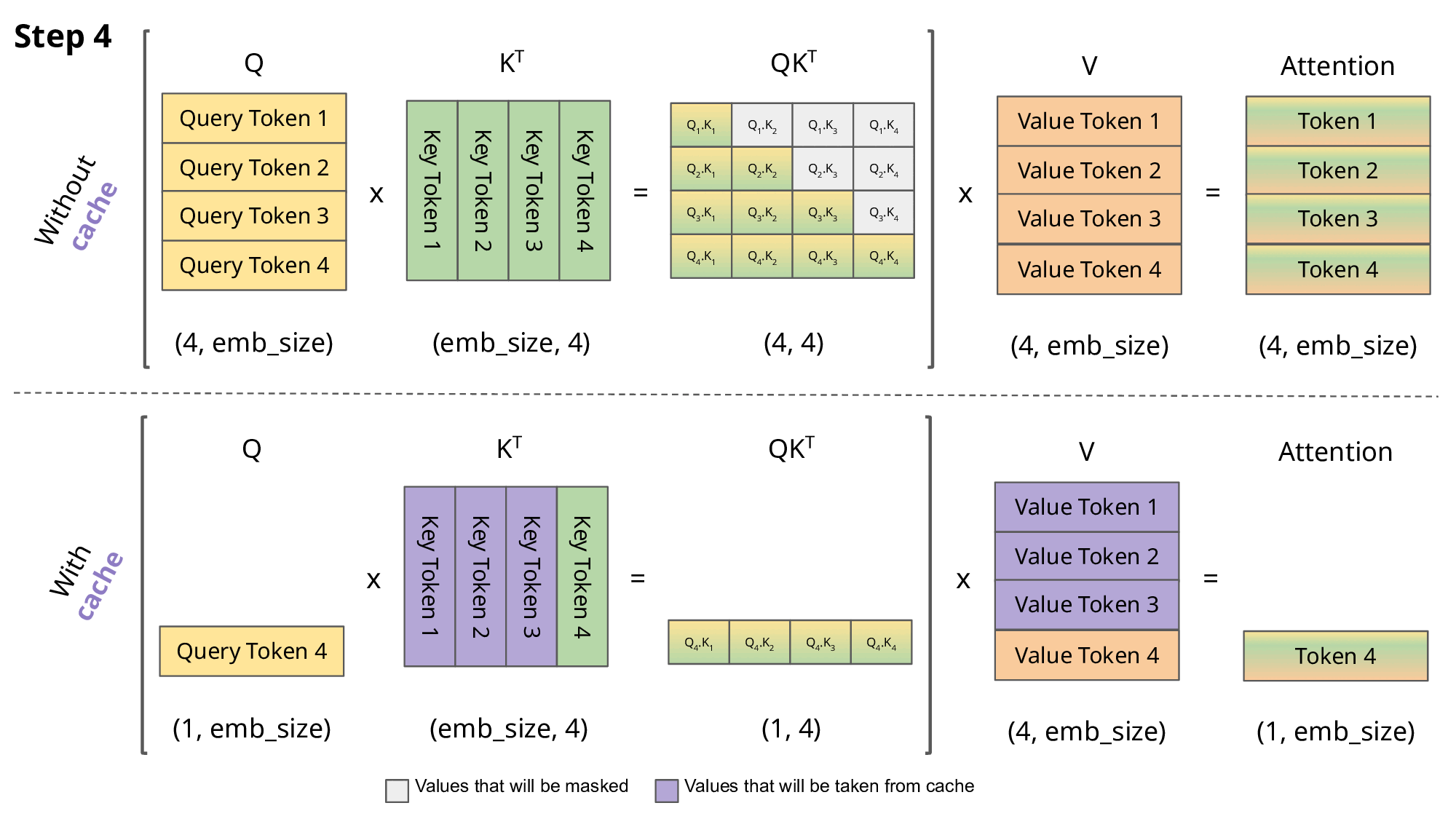
Inference from a prompt (starting from many token)
Question: if the sequence length the transformer is trained on is 16, and the inference input prompt is of length 18 or 20 or anything, the input to start sampling is always last 16 tokens. ([-T:]). Does KV-caching still helps?
If the transformer is trained on sequences of length 16 and the inference input prompt is longer (e.g., 18), the model will typically use a sliding window approach, processing the input prompt in chunks of 16 tokens at a time. This is known as “ truncation” or “windowing”.
In this case, the input to generate the inference would be the last 16 tokens of the prompt (using slicing notation, input_prompt[-16:]).
KV caching still helps in this scenario. Even though the input prompt is longer than the training sequence length, the model is still generating output tokens one at a time, and the attention mechanism needs to consider the previous 16 tokens when generating each new token.
By caching the Key (K) and Value (V) matrices for each token generation step, KV caching reduces the computational cost of recomputing these matrices from scratch at each step. This is especially important when generating long output sequences, as the attention mechanism needs to consider an increasing number of previous tokens.
Why Query (Q) is not cached
As the next generated token is used as query to the next prediction, we need to recompute this every time. We don’t know the future prediction, do we? :)
Sources
- As this blog is an personal notes, this medium blog is an awesome read: kv-caching explained