Gradient-Checkpointing
You got a very deep neural network to train, lets say wide 128-layers. Does it fits in memory? Yes (barely). The activations and gradients in forward and backward pass respectively takes a lot of memory. But you want to train more deep NN. Why? because, we build the compute (stack more layer) ~= win. (scaling hypothesis) / Blessing of scaling.
See the original gradient checkpointing implementation.1
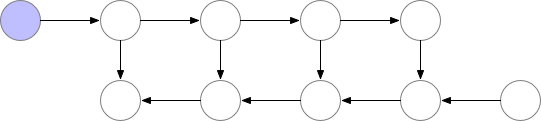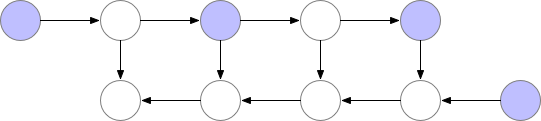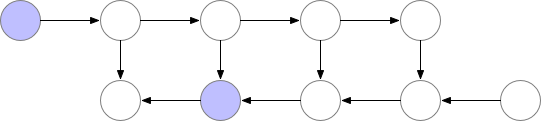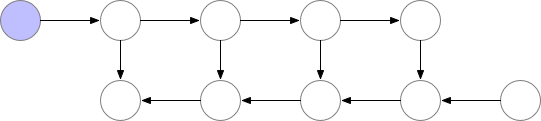
Here is a visualization of vanilla training:
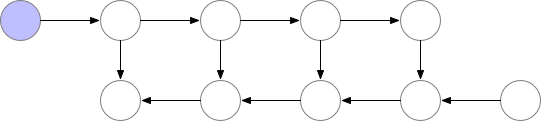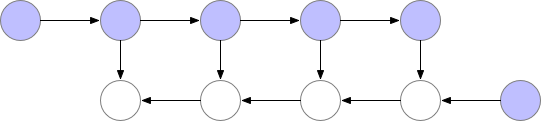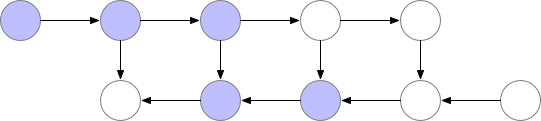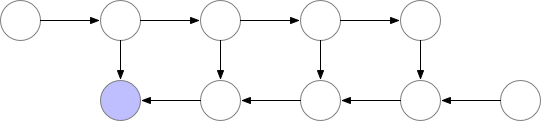
However, if the cost of computation < cost of memory, we have limited memory and we are willing to recalculate those nodes (attentions and gradients) then we can save a lot of memory. We can simply recompute them when we need in the backward pass. We can always recompute the activations by running the same input data through a forward pass. See below:
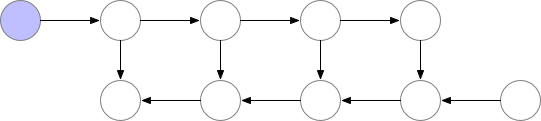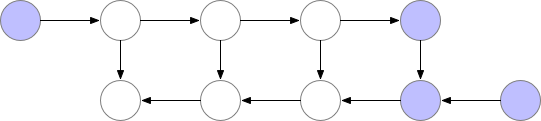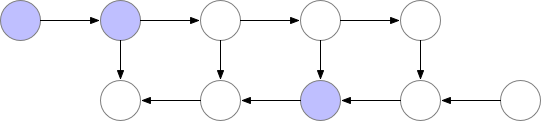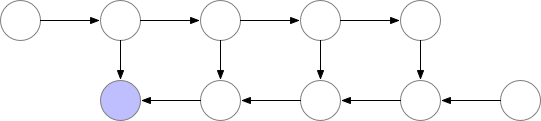
There is a lot of compute waste. For N-layers there would be N extra forward pass. Gradient checkpointing1 is something in between this two methods, where we recompute the forward pass but not too often.
There are checkpoints nodes in the memory during the forward pass, while the remaining nodes are recomputed at most once. After being recomputed, the non-checkpoint nodes are kept in memory until they are no longer required1.
Optimal checkpointing selection
Marking every \(\sqrt{n}\) -th node as a checkpoint optimizes memory usage, scaling with the square root of the number of layers.