Case Study on Transformer-based architecture
work in progress. publishing this but will be updated every few days, as I learn new stuffs. learning > blog
I am learning how the transformer-based architectures got evolved from 2017 (“Attention is all you need”) till today (May 2024). So, I thought why not write a case-study like this (by Andrej Karpathy).
Table of content
- How can unsupervised learning work?
- GPT (June 2018)
- BERT (October 2018)
- Transformer-XL (September 2018) & XLNet (June 2019)
- GPT-2 (February 2019)
- Sparse Transformers (April 2019)
How can unsupervised learning work?
Why it works? Generalization?, hypothetically…
GPT (June 2018)
TODO
https://openai.com/index/language-unsupervised/
BERT (October 2018)
Google introduced BERT, which stands for Bidirectional Encoder Representations from Transformers. It is another language model based on Transformer architecture but unlike recent language models BERT is designed To pretrain bidirectional representation from unlabeled text. As a result, the pre-trained BERT model can be fine tuned with just one additional output layer to create state of the art models for a wide range of tasks such as question-answering, system language inference. Without any substantial task-specific architecture modification.
Language model pre-training has been shown to be effective in the recent years. There are two existing strategies for applying pre-trained language representation to down-stream tasks:
- feature-based: Uses task-specific architecture, example adding a layer at the end of the trained model and train them for downstream task.
- fine-tuning based: basically transfer learning? (like used in GPT). The trained weights gets updated as well finetuned on a task specific dataset.
The two approaches share the same objective function during pre-training, where they use unidirectional language models to learn general language representations. But the authors of paper argues:
Current technique limit the potential of pre-trained representations. Especially for fine tuning the issue stems from the unidirectional nature of standard language model like openai’s GPT. Which only allows token to attend from past. This restriction hampers performance and task requiring bidirectional context, such as question answering.
Architecture. The architecture was based on original Transformer based on Vaswani et al. (2017). BERT-base parameters equals to GPT-base for comparision purposes. But BERT uses bidirection self-attention. While the GPT uses constrained self-attention where every token can only attend to context to its left, BERT can see in both direction. This means BERT uses the Encoder-only part of the Transformer.
PreTraining BERT Implementing this (encoder-only model) however was challenging. Unfortunately, standard conditional language models can only be trained left-to-right or right-to-left, since bidirectional would allow each word to indirectly attent itself (they called it “see itself”) and with this instead of learning important features, the model would cheat and wont learn anything at all. In order to fix this, BERT is trained using two unsupervised task.
- TASK #1: Masked Sequence: they masked some percentange of the input tokens at random, and then predict those tokens. This procedure is called “masked LM (LML)”. Introduced back in 1952 (Taylor, Cloze task in the literature).
- TASK #2: Next Sequence Prediction:
TODO
Input/Output representations BERT can handle, [CLS], [SEP], [MASK] and [PAD]. TODO explain the input and output of BERT.
I pretrained a BERT model from scratch. see :)
Transformer-XL (September 2018) and XLNet (June 2019)
TL;DR: In the next section, you’ll learn that GPT-2 has a summarization problem - it struggles with long-term dependencies, leading to non coherent with words like
color/log/hat/caretc. While I couldn’t find a specific paper addressing this issue, it’s related to the limited attention scope within the context window. TransformerXL tackles this problem by increasing long-term dependencies without expanding the context window. Additionally, it introduces a new positional encoding technique called Relative Positional Encoding, which replaces the absolute positional encoding used in the original Transformer. This approach has been adopted in later models like OpenAI’s “Fill In the Middle” (2022).
In the vanilla Transformer, attention doesn’t flow between context windows. Consider a context length (sequence length) of 64, where 64 tokens constitute a single segment during training. In this scenario, the Transformer is unable to attend to long-term dependencies, as it’s limited by the context length of 64. The next segment will have no information about the previous sentence. As a result,
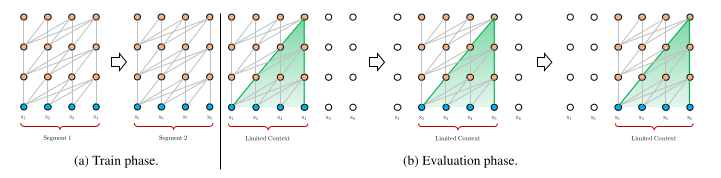
The fixed context length means the model cannot capture longer-term dependencies beyond the predefined context length. Moreover, fixed-length segments are created by selecting a consecutive chunk of symbols without respecting sentence or semantic boundaries. This leads to a lack of necessary contextual information, making it difficult for the model to accurately predict the first few symbols. Consequently, optimization is inefficient, and performance suffers. They refer to this issue as context fragmentation.
And during inference, the vanilla model consumes a segment of the same length as in training, but only makes one prediction at the last position and in the next step, the segment is shifted to the right by only one position. We lost the context detail again for the next prediction.
TransformerXL used caching of Key and Value attention computation to speed up inference. I think originally introduced in “Edouard Grave, et al. 2016 Improving neural language models with a continuous cache”.
-
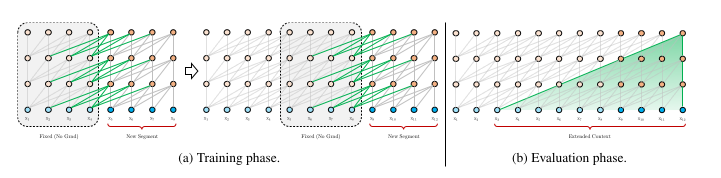
Introducing Segment-Level recurrence with state reuse.
To address the limitation of using fixed-length context, they propose to introduce a recurrence mechanism to the Transformer architecture. During training, the hidden state sequence computed for the previous segment is fixed and cached to reuse as an extended context when the model processes the next new segment is fixed and cached to be reused as an extended context when the model process the next segment. If we assume two consecutive segments of lengthL, thenS_t=[x_t,1 , ... , x_t,L]and
S_t+1=[x_t+1,1, ... , x_t+1,L].Say the hidden state/calculated attention “memory” of the first segment is given by:
h_t^nwherenis the n-th layer hidden state. Then we can use this to calculate the hidden state of next segment.h^~=[ SG(h_t^n) ◦ h_t+1^n-1 ]Where
SGis “Stop gradient”, similar totorch.no_grad, because we dont want to calculate the gradient for previous context, we store the cache as a constant with no backward graph.◦indicates concat within the context dimension, say the input is of shape,B,T,Cand after concatination of two segments, it would beB,2*T,C. (This notation is from my old blogs, where B is the batch size, T is the sequence length/context length, C is the embedding size).We use
h^~to calculateKeyandValuerepresentations. Not theQueryof course.K_t+1^n=h^~ * W_k^t
V_t+1^n=h^~ * W_v^t
Q_t+1^n=h_t+1^n-1 * W_q^tWhy not cache Q? That’s a mystery. or find out here.
-
Relative positional encodings.
With the above achievement (reusing the previous context attention) we just created another problem. Notice, the positional encoding of current segment’s first token is equal to the previous segment’s first token.

makes model confuse? ~from https://vimeo.com/384795188
To fix this the authors introduced the concept of “relative positional encoding” to capture the relative position information between the element in the input sequence. This is different from The absolute positional encoding used in the original transformer model, which represents the absolute position of each element in the sequence.
The idea behind “relative positional encoding” is to represent the positional information as a relative distance between elements rather than their absolute positions.
This is particularly useful for processing sequence as it allow module to generalize better. The sequence of different length.Original transformer: E = VE + PE (Vocab Embeddings + Positional Embeddings) TransformerXL, incorporates directly VE and PE into attention: Attn = F(VE,PE) > similar sinusoidal functions are used to generate positional embeddings > additional relative_pos and relative_key encodings are also generated, along with Q, K and V - Q, K, V, rel_key and rel_pos - relative_pos: Learnable relative positional embeddings. (Parameter) - relative_key: Derived from relative_pos using a linear transformation. (Linear) > 2 attn scores are calculated: content-based & position-based - content-based: Q @ K.T - position-based: rel_k = rel_pos -> rel_key Q @ rel_k.T > attn = content-based + position-based (continue attention scale, tril, softmax, V ...)
GPT-2 (February 2019)
TODO-- easy already read the paper
Sparse Transformers (April 2019)
The Transformer architecture, introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017, is a widely used neural network model for natural language processing tasks. However, its computational complexity and memory requirements grow quadratically with the sequence length, which can become a limitation for long sequences.
- Given sequence of length
n.- number of computations required to process attention weights:
n x n = n^2 - Memory required to store the intermediate results and attention weights grows quadratically
- number of computations required to process attention weights:
- Sparse Transformer reduced this complexity to
n x sqrt(n)
Some understanding from this paper about the Transformer architecture. Transformer autoregressive model is used to model joint probability of sequence x = {x1, x2, x3, ... xn } as the product of conditional probability p(xn+1 | x).
- It has the ability to model arbitary dependencies in a constant number of layers. As self-attention layer has a global receptive field.
-
It can allocate representation capacity to input regions, thus this architecture is maybe more flexible at generating diverse data types than networks with fixed connectivity patterns.
- They trained 128-layer Transformer on image and found that the network’s attention mechanism is able to learn specialized sparse structures
- early layer learned locally connected patterns, which resemble convolution.
- layer 19-20 learned to split the attention across row and column attention
- several attention layers showed global data-dependent access patterns
- layer 64-128 exhibited high sparsity, with positions activating rarely and only for specific input patterns.

Learned attention patterns from a 128-layer network
- In a fully connected attention mechanism, for each
queryati'thposition needs to attend all thekeysin the sequence. This dense Attention Matrix has sparse attention patterns across most datapoints, suggesting that some form of sparsity could be introduced without significantly affecting performance.
The paper introduced three key techniques to solve the quadratic complexity issue of standard Transformer when modeling long sequence:
-
Factorized self-attention
Factorization of self-attention is breaking them down into several faster attention, when combined can approximate the dense attention. This is applied on sequence of unprecedented length. Original self-attention involves every position attending, factorized self-attention splits attention into multiple heads, each focuses on a subset of positions. Mathematically, instead of having each head attend to all positions in the input sequence, we restrict it to a subset, for example, if there isnpositions in the input sequence, we don’t need each head to look at allnposition instead, each head can look approximately \( \sqrt{n} \) positions.The size of each attention set
Ais proportional to the square root of the total number of positions.Two Dimentional Factorized Attention
- proposed for structured data like images or audio.
Strided Attention:One head attends to previous \(l\) positions, another attends to every \(l\)-th position (stride).- Strided attention is beneficial for structured data but less effective (fails) for unstructured data like text.
Fixed Attention:For unstructured data a fixed pattern is used where each position attends to specific past positions, aiming to ensure relevant information is propogated efficiently.- Scaling to 100 of layers: Used pre-activation residual block.
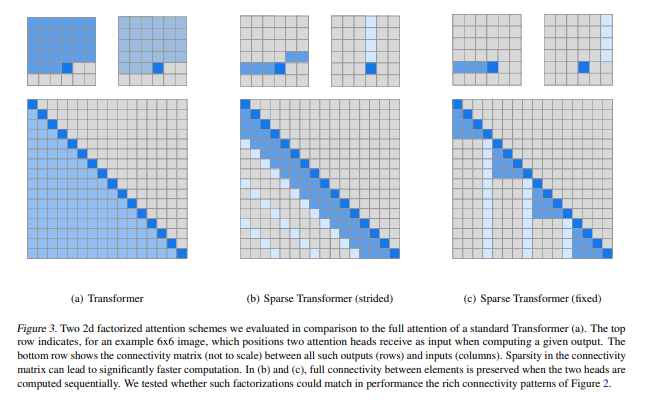
from the Sparse Transformer paper
- Reuse attention matrices (saving memory)
- Gradient checkpointing is particularly effective for self-attention layers when long sequences are processed, as memory usage is high for these layers relative to the cost of computing them. Using recomputation alone, we are able to train dense attention networks with hundreds of layers on sequence lengths of 16,384, which would be infeasible on modern hardware otherwise.
- Mixed precision training
Storing weights in single precision floating-point (32-bit), but compute network activations and gradients in half-precision (16-bit). (Micikevicius et al., 2017).-
Dynamic loss scaling. When we use half precision to calculate activations and gradients, they are more prone to underflow (very small becoming 0) and overflow (very large becoming infinity). To fix that, when calculating gradient, the loss value is scaled (multiplied) with a large number, before backward pass. We then calculate the gradients. Unscale the gradients by dividing them by the scale value. Update the parameters using unscaled gradients.
Dynamic loss scaling is adaptive, meaning scale value is chosen dynamically. Initialized with a large number like 1024. After each backward pass, we check if the gradients contains any NaNs or Inf. If overflow, reduce the scaling factor by factor of 2. If no overflow, increase the scaling factor optionally. [Pytorch docs]
-
- Efficient sparse attention kernels
- Fused Softmax kernel
Typically, the softmax operation is computed as a seperate kernel or function that requires writing, loading, computing and again writing. This paper proposes fusing the softmax operation into single kernel that uses registers to avoid reloading inputs. This means that the softmax operation is computed directly in the kernel, without storing and loading. - No need to calculate the upper triangular in attention, as it is never used in autoregressive task.
- Fused Softmax kernel